[Elasticsearch] 엘라스틱서치 벼락치기(1) - 기본개념
오랜만에 포스팅이다.
이번 포스팅은 사내에서 Elasticsearch 관련 내용 발표를 위해 "시작하세요! 엘라스틱서치"서적을 기반으로 학습하고 이해한 내용을 정리하는 포스팅이다. 사내에서는 이미 ELK 스택 을 구성해서 Elasticsearch를 사용하고 있지만 Kibana를 이용해서 필요한 정보를 검색만 했지 Elasticsearch 에 대해서는 따로 학습해본 적이 없었기 때문에 이번이 좋은 기회였다.
Elasticsearch 역시 내용이 많기 때문에 시리즈로 나눠서 정리할 예정이다. 시리즈가 잘 마무리 되면 사내에 공유도 할 예정이다.
Elasticsearch 개념
우선 Elasticsearch 가 무엇인지 개념부터 확인해 보자. 공식사이트와 위키에서 조회하면 다음과 같은 내용이 나온다.
"Elasticsearch 는 확장성이 뛰어난 오픈소스 풀텍스트 검색 및 분석 엔진입니다. 방대한 양의 데이터를 신속하게, 거의 실시간으로 저장, 검색, 분석할 수 있도록 지원합니다. 일반적으로 복잡한 검색 기능 및 요구 사항이 있는 애플리케이션을 위한 기본 엔진/기술로 사용됩니다."
"Elasticsearch 는 루씬 기반의 검색 엔진이다. HTTP 웹 인터페이스와 스키마에서 자유로운 JSON 문서와 함께 분산 멀티테넌트 지원 전문 검색 엔진을 제공한다."
공식사이트와 위키에서 쉽게 설명해줬지만 다시 한번 정의해보자면 Elasticsearch 는 "루씬(Lucene)이라는 검색 라이브러리를 기반으로 검색 기능을 제공하는 오픈소스 검색엔진이다." 라고 이해하면 되겠다.
Elasticsearch 는 데이터를 저장할 때 검색에 유리하도록 데이터를 역인덱스(Inverted index) 구조로 저장하기 때문에 데이터 검색에 한해서는 기존에 RDB 보다 성능이 뛰어나다. Elasticsearch 에서는 데이터를 저장하는 과정을 색인(Indexing) 한다고 표현한다. 역인덱스 구조의 예시를 보자면 다음과 같은 문장이 있을 때 아래와 같이 분할해서 저장한다.
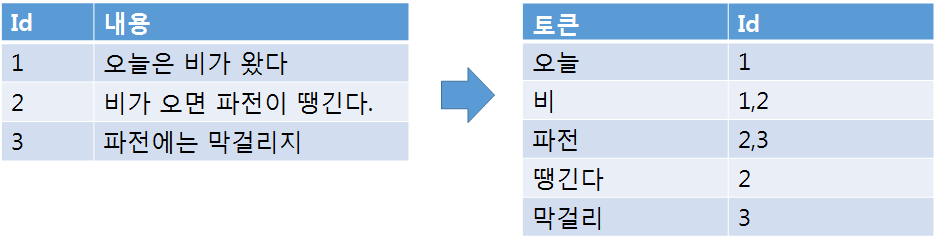
또 다른 예시로는 우리가 읽는 기술서적의 제일뒷면 색인 페이지라고 이해하면 편한다.
엘라스틱서치 클러스터 구조(Elasticsearch Cluster)
앞으로 자주 사용할 엘라스틱서치 클러스터의 용어 및 개념에 대해서 알아보자.
엘라스틱서치 클러스터는 다음과 같은 요소들로 구성되어 있다

도큐먼트(Document)
Document 는 Elasticsearch 저장의 기본 단위인 JSON 개체이다. 관계형 데이터베이스와 비교해보자면 테이블의 Row 와 같다고 생각하면 된다. Document 는 키와 값으로 정의된 필드(Field)들로 구성되어 있는데, 키는 필드의 이름이며 값은 String, Number, Boolean, Object, Array 등의 다양한 유형일 수 있다.
Document 에는 다음과 같이 문서를 구성하기 위한 예약된 필드가 포함되어 있다.
- _index - Document 가 저장되어 있는 Index 정보
- _type - Document 의 유형을 나타내는 정보
- _id - Document 의 유니크한 고유값
타입(Type)
Type 은 Document 를 유형별로 모아놓은 집합이다. 관계형 데이터베이스와 비교해보자면 데이터베이스의 테이블과 같다고 생각하면 된다. Elasticsearch 7.0 미만에서는 하나의 Index 에 여러개의 Type 을 가질 수 있었는데 여러 가지 문제로 인해 7.0 부터 는 단 하나의 Type(_doc) 만 가질 수 있게 되었다. 이에 대한 내용은 여기서 확인할 수 있다.
인덱스(Index)
Index 는 Elasticsearch 의 가장 큰 데이터 단위이고, 관계형 데이터베이스와 비교하자면 데이터베이스와 같다고 생각하면 된다. Elasticsearch 에서는 원하는 만큼의 Index 를 가질 수 있고, 각 Index 는 고유한 Document 를 보유하게 된다.
또한 Index 는 다음과 같이 2가지 유형으로 구분할 수 있다.
- 샤드(Shard)
- 샤드는 간단히 말해서 단일 루씬 Index 이다. 이는 Elasticsearch 의 확장성을 용이하게 하기 위해 필요하다.
Index 는 저장할 수 있는 Document 의 제한이 없기 때문에 호스팅 서버의 제한을 초과하는 디스크 공간을 차지할 수 있다. 이럴 경우 발생하는 문제를 대응하기 위해 Index 의 데이터를 분산해서 저장하고 이렇게 나뉜 조각들을 샤드라 한다. 샤드와 샤딩 개념에 대한 내용은 여기를 참고하자. - 복제셋(Replicas)
- 복제셋(Replicas) 는 이름에서 알 수 있듯이 Index 의 분산된 Shared 들을 복사한 것이다. 이는 노드의 문제가 생길 때 백업시스템으로 사용되며, 읽기 요청을 처리할 수 있으므로 검색 성능을 높이는데도 도움을 준다. Elasticsearch 에서는 가용성을 보장하기 위해 원본 샤드와 복제셋을 같은 노드에 놓을 수 없다.
노드(Node)
Node 는 데이터를 저장하고, 색인(Indexing) 하는등의 중요한 역할을 하는 Elasticsearch 인스턴스이다.
Node 는 다음과 같은 유형들로 나눠서 각자의 역할을 수행한다.
- Data Node - 데이터를 저장하거나 검색과 집계 등 데이터와 연관된 작업을 한다.
- Master Node - 노드의 추가, 제거 등 클러스터의 관리 및 구성 작업을 담당한다.
- Ingestion Node - 색인 전에 Document 를 사전처리하는 용도로 사용한다.
- Machine learning Node- 머신너링 작업을 가능하게 하는 용도로 사용한다.
모든 Node 는 기본적으로 Master, Data, Ingestion Node 가 될 수 있지만, 클러스터 규모가 커질수록 각 Node 들을 단일 유형으로 구분하는 게 좋다. 자세한 내용이 궁금하면 여기를 참고하자.
클러스터(Cluster)
Cluster 는 하나이상의 Node 로 구성되어 있어야 하며 그 하나의 Node 는 Master Node 의 역할을 할 수 있어야 한다.
Cluster 라는 용어에서 알 수 있듯이 여러 개의 Node 가 모여서 하나의 시스템처럼 동작하게 하는 Node 의 집합이다.
오늘 알아본 내용들을 요약하자면 다음과 같다.
- Elasticsearch 는 루씬 기반의 검색엔진이다.
- Elasticsearch 는 데이터를 역인덱스 구조로 저장하기 때문에 검색에 유리하다.
- Elasticsearch Cluster 에는 다음과 같은 요소들이 존재하고, 하나이상의 Node 로 구성되어 있다.
- Node
- Index
- Shard
- Replicas
- Type
- Document
오늘은 여기까지~
누군가에게 도움이 되었길 바라면서 오늘의 포스팅 끝~